Conversational Search for Cultural Heritage part 2
I'd called the previous blog post 'Conversational Search for Cultural Heritage' but the implementation in it was not really much of a conversation, as I was just sending individual queries/prompts one at a time to the LLM with RAG, with no real history between the queries. So I wanted to make good on my claim for "conversational search" by developing this more.
I've had to combine a few more tutorials for this and also am using the Gradio interface tools:
Gradio - https://www.gradio.app/guides/creating-a-chatbot-fast
https://python.langchain.com/docs/tutorials/qa_chat_history/ - Adding in chat history
https://python.langchain.com/docs/how_to/qa_sources/#conversational-rag - maintain RAG response between queries
(the latter took a long time to work out, and I'm still not sure if it's workingcorrectly or if it's sending a query to the vector search every time which is slowing down every response).
I also wanted to make use of the DeepSeek model, given it's the model of the moment (and it would let me move the LLM querying to a local query instead of being API rate limited as the Mistral one I was using before was). But at the moment via Ollama it doesn't support tooling, hopefully this will be resolved soon, so I switched instead to using Qwen2.5 (7B) via Ollama. This stopped me hitting rate limits, but I don't have a fast computer/GPU so it's slow to get any response (hence the recording of the chat is not real-time, as it took about 2 mins to ask/answer 3 questions!).
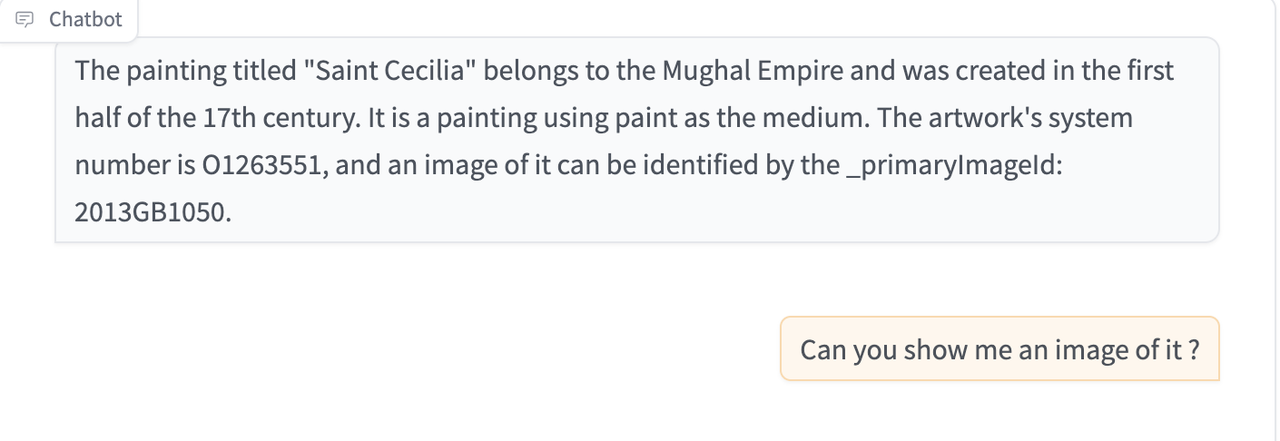
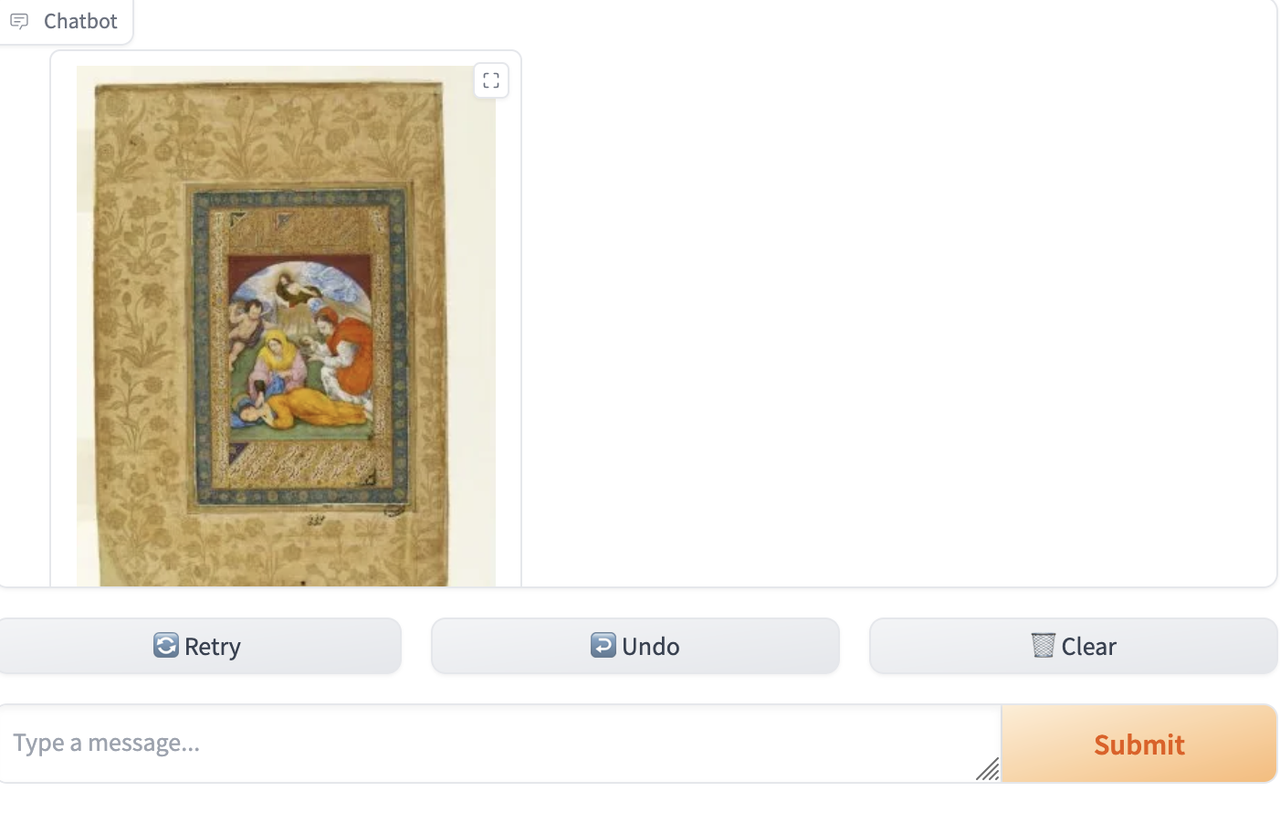
I added into the LLM prompt some special instructions for handling requests for images, telling it to return the image asset ID only, which I can then check for (as it's a fixed format) and instead of returning text, switch to returning the image instead (using the V&A IIIF image API).
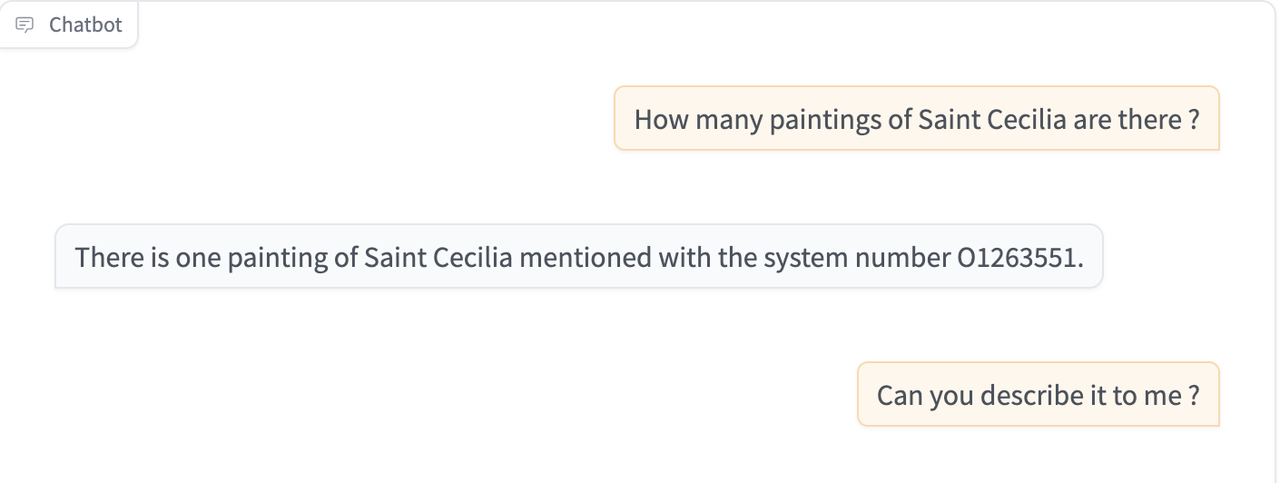
I also switched the dataset I'm using from 100 dog related objects to 100 objects depicting saints, hence the query below about Saint Cecilia.
With all that done, this allowed me to get conversations like this:
(screenshots while I put the video somewhere, or see it on my bluesky post)
(note - there are actually two objects depicting Saint Cecilia in the 100 objects dataset, but the vector search only returns one for some reason, so the LLM is correct given the data it receives)
I think this is getting towards a slighty more conversational search that might be of some interest to some users wanting to explore a collection. But the restrictions I noted in the first blog post remain, the RAG approach limits the amount of knowledge that can be sent to the LLM so this (for the moment) would suit subsets of the collection rather than the whole. I'm going to think about what different types of collection search/discovery and AI techniques might be useful in the next post.
Notebook (tidying up, to follow, I promise!):